




IQVIA NLP Platform
Insights are trapped in mountains of text. NLP sets them free.












We are excited to share in this blog post the release of our IQVIA LLM Trustworthiness Toolkit. This plug-and-play module enhances reliability in LLM applications, offering strategies for confidence, consistency, and transparency. Model, data, and domain agnostic, this toolkit enables more dependable, healthcare-grade AI™ across diverse applications.

Large Language Models (LLMs) have emerged as powerful tools in natural language processing, and AI more generally, revolutionizing how we interact with machines, information, and knowledge. However, their impressive capabilities come with significant challenges. Indeed, as these models generate human-like text with remarkable fluency, they also introduce uncertainties that should be accounted for. From "hallucinating" convincing but false information to exhibiting inconsistent behavior across similar queries, LLMs often leave us questioning their reliability. Recent research has highlighted several concerning issues: LLMs like ChatGPT can mislead, producing text without concern for its accuracy, potentially leading to the spread of misinformation. The "Skeleton Key" jailbreak attack can cause LLMs to ignore safety guardrails and generate unsafe content. Stanford researchers found that GPT-3.5 and GPT-4 can still mislead to produce toxic, biased outputs and leak private data, despite some improvements.
These trustworthiness issues risk eroding user trust and limiting the impact that such technologies can achieve. But the trustworthiness of LLMs is particularly critical in healthcare, where the stakes are high and the margin for error is low.
One approach to enhancing user trust in statistical models is augmenting model outputs with confidence scores. Indeed, this approach has been used for decades with discriminative models. However, while discriminative models provide scores for a fixed set of outcomes, LLMs are fundamentally different. Indeed, under the hood LLMs such as ChatGPT employ an iterative “decoding” step to generate text sequentially by selecting next tokens with the highest score at each step based on all the previous input and generated tokens. This dependence of the output of generated text on the previous text it generated in the same sequence makes it inherently difficult to obtain a single, meaningful confidence score for an entire generated response.
Confidence scores in LLMs are not straightforward
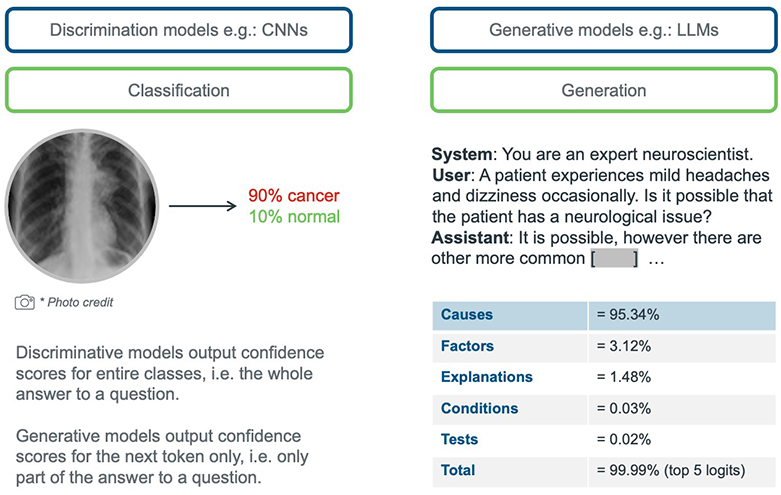
With that in mind, how can we harness the potential of LLMs while ensuring their outputs are dependable enough for healthcare applications?
IQVIA's NLP team is driven by the transformative potential of AI in healthcare. As a leader in this space, we've long recognized AI's capacity to revolutionize healthcare delivery and improve patient outcomes. As such – there are numerous examples of working hand in hand with our customers to bring patient impact from AI deployment. A recent and notable example in clinical decision support resulted in our receipt of the 2023 AI breakthrough award for best innovation in healthcare.
Providing data transformation for unstructured textto the life sciences industry for over 20 years

Our extensive work and direct involvement in these complex problems have led us to develop the IQVIA LLM Trustworthiness Toolkit, which tackles key technical barriers to realizing the full potential of LLMs in healthcare. Specifically, the following trustworthiness challenges are being addressed:
Calibrating confidence in complex scenarios
Ensuring consistency across interactions
Enhancing transparency and explainability
At IQVIA, we're developing novel applications of our LLM Trustworthiness Toolkit to address healthcare-specific challenges, focusing on enhancing confidence in AI-generated outputs for important healthcare domain problems such as:
Interested in applying this toolkit to your work? We'd love to hear from you. Contact us for more information or to discuss your specific use case.
Insights are trapped in mountains of text. NLP sets them free.