
















- Blogs
- Generative AI in Life Sciences: Evaluating LLMs/GPT for summarization of Primary Market Research
Since its launch in November 2022, chatGPT has taken the world by storm. By January 2023, the AI-powered Q&A engine had already amassed over 100 million users, leading many to view it as the next revolution in search engines considering the integration with Microsoft Bing – it has even (at least temporarily) led to a restructure of essay requirements in secondary schools and universities.
We are excited to announce that here at IQVIA, we have been working on multiple use cases using Large Language Models like GPT, in a bid to provide our clients with the best possible services.
A significant portion of the strategic work for which IQVIA is commissioned relies on the application of domain expertise, complemented by hypothesis-driven primary research with industry experts, decision makers, and influencers (not limited to healthcare system payers and former payers, key opinion leaders, pharmacists). The hypothesis validation is essential, but the process of synthesizing and analyzing the findings, especially when the sample size is extensive, can be cumbersome.
Using a series of prompt engineering techniques that likely involved designing and refining the input, we have created a new GPT-based tool to help our teams synthesize the transcription data we collect during Primary Market Research. Summarization at the click of a button.
Deploying GPT on interview transcripts – assessing the quality
To gain more internal buy-in for the tool, we wanted the future users to assess the quality for themselves, in a blinded manner. Posting an internal survey (n=30), we had the respondents assess four summaries. Two were generated by the project team, two were generated by GPT3.5 (text-davinci-003). Each summary differs, in the sense that as human recollection and response changes, GPT also does not issue verbatim responses each time it is queried.
They were assessed based on the following criteria:
- Relevance: How consistent the summary is
- Factuality: Whether the generated summary contains only statements entailed by the source text
- Coherence: Whether the text builds from sentence to sentence to a coherent body of information about a topic
- Semantic Coverage: How much of the important information from the original text is included in the generated summary
The results were impressive.
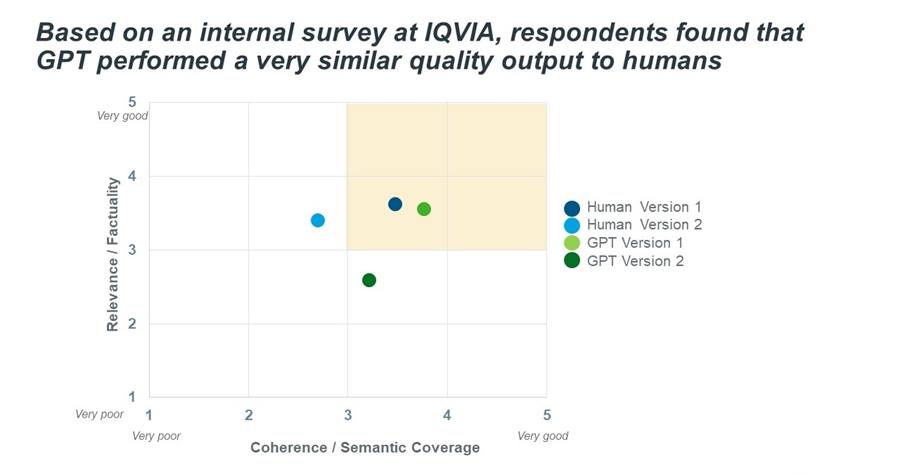
Whilst at the point of survey construction we had been strictly utilizing prompt-engineering techniques and had not yet employed indexing methods let alone fine-tuning (therefore GPT lacked the general context of the overall project content), it was able to generate a factual summary from the raw input data. If anything, the respondents noted that one of the GPT summaries was more coherent than the human generated versions, and overall rated the quality very similar to that of the human.
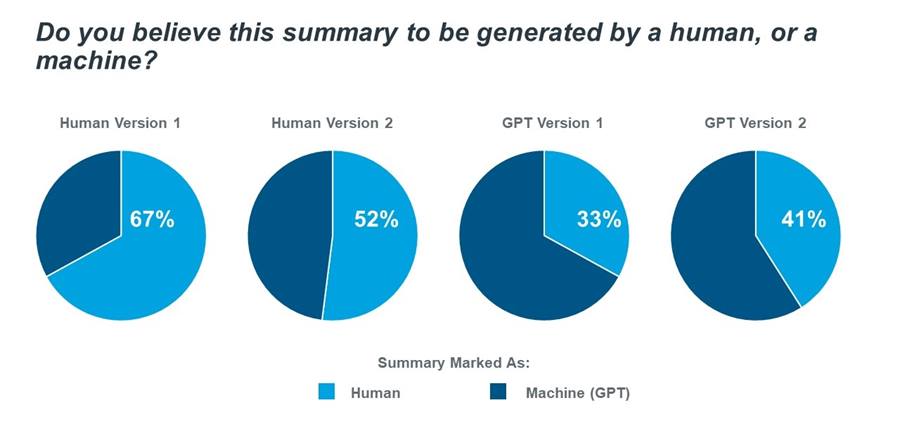
Because the study was blinded, respondents were then asked to mark whether the summary was human generated, or GPT generated. Perhaps not surprisingly, they could identify that it was generated by the model simply based off the fact that it was so articulate, something that lacked in the more informal human generated versions.
What else have we learned?
We are ‘cautiously’ optimistic. Whilst deploying GPT on transcripts has proven beneficial, generating more time for our strategy consultants to apply critical thinking, we are aware that the model outputs can be temperamental, with loss of nuance and even occasional ‘hallucinations’, i.e. when the model outputs a seemingly coherent piece of text, that is factually incorrect. In other words, GPT can’t be used straight ‘out-of-the-box’ in Life Sciences. To explain in more detail, we asked chatGPT:
While GPT has shown impressive performance in various language tasks, it still requires indexing and prompt engineering for several reasons.
First, GPT generates text based only on the context it has been trained on. Therefore, it is crucial to provide GPT with a prompt that adequately sets the context for the generated text.
Second, GPT processes text in chunks, and indexing is necessary to access the chunks efficiently. GPTs architecture relies on a sequence of tokens to represent text, and indexing involves creating an efficient mapping between the tokens and their positions in the input text.
Finally, indexing and prompt engineering can improve the efficiency and effectiveness of GPT for specific tasks. For example, in question-answering tasks, a well-crafted prompt can help GPT generate a concise and accurate answer more quickly. Similarly, indexing can speed up the text generation process making it possible to generate longer and more complex texts without sacrificing performance.
Where are we headed?
Here at IQVIA, we know not to trick ourselves when we’re making a lot of progress.
We initially rolled out the capability in a less sensitive area to test, and we have already moved on to successful theme generation and are building a Q&A capability on top of transcripts. Progress has been significant, but we continue to keep the human in the loop to reinforce the model and to make final selections on the preferred outputs.
Large Language Models like GPT have the ability to make an incredible impact. However, it is important that we assess reliability, safety, trust and bias of these models if we in turn are to be trustworthy in what we’re talking about. Therefore, we are investing heavily to ensure that when we apply GPT to other, more sensitive use cases, the margin for error is minimal.
As we continue to accelerate innovation for a healthier world, rest assured there is more to come from us here at IQVIA. Watch this space…
For more information, please reach out to Lauren Poole